How Search Engines Analyze Web Pages for Search Rankings?
Search engines like Google want to ensure that the quality of the web pages that show up in their search results are high, and that search engine users will be satisfied with them. If their document (web page) analysis shows strong signals that indicate poor-quality content, it can negatively impact the rankings and visibility of those web pages online.
There are many different ways to analyze content quality, and it’s hard to know exactly what the search engines use, but in this article I will explore what we do know about what Google is doing in this area, as well as many other concepts that you can use to think about your own web page quality.
What We Know About How Google Evaluates Content Quality
So, what are the signals and related search updates that apply to document analysis? Besides content quality, a brief list would include reading level, keyword usage (stuffing), content sameness, ad density, page speed, and finally, language analysis factors.
In the end, for search engines, document analysis is about improving the search user’s experience. Let’s break it down.
The Panda Algorithm
When content quality is mentioned, nearly everyone involved in SEO immediately thinks of the Google search ranking algorithm update, Panda.
Since its introduction in February 2011, Panda went through several iterations before finally being folded into Google’s core search ranking algorithm nearly five years later, in January 2016.
Google’s Panda algorithm originally targeted shallow or low-quality content represented by the many content farms of the day, as well as websites that scraped (copied) others content or had low levels of original content.
Of course, Panda still takes aim at such obvious web spam by demoting search rankings, but the algorithm is much more sophisticated today. Now that Panda has become baked into Google’s overall search ranking algorithm, it’s become an integral part of weighing content quality factors via document analysis.
And one obvious tip-off indicating low-quality content in document analysis is poor editorial quality. Let’s look at some other factors that might go into web page quality.
Manual Review by Google’s Quality Raters
In 2001, the first version as we knew it of Google’s Search Quality Rating Guidelines was leaked on the web (some speculate intentionally). Google’s search evaluation team uses this internal guide to manually review and rate the quality of web pages.
The purpose of the search evaluation team and the manual is to determine what quality looks like, and in turn, use those benchmarks as a feedback loop for Google engineers responsible for developing ranking algorithms.
For example, if an engineer has an idea for tweaking the algorithm, the search evaluation team can help determine if that change has actually improved the search results.
Since that first leak of the Search Quality Rating Guidelines, several other, more current versions also surfaced on the web until Google finally made its full manual officially available to the public, starting in 2015 with several updates since.
Keyword Stuffing and Vanilla Content
Keyword stuffing is now so pass that it seems barely worth a mention. A relic of the AltaVista search engine of days of old, it refers to repeating the same keyword over and over on a web page to achieve higher rankings for the term.
The hangover from this tired practice is the notion of keyword density. Keyword density is a percentage of the occurrences of a given keyword (or phrase) on a given web page per the total number of all the words of that page. This is also an out-of-date concept.
Keyword stuffing/keyword density is an activity that’s geared towards the search engines rather than the end user. The search engines have long discouraged this practice, as it does not enhance the user experience.
Keyword stuffing, or excessive keyword density, especially when combined with little to no use of synonyms for the key phrase, is a strong indicator of low-quality content.
Similar in effect is content sameness or vanilla content that doesn’t stand out from other pages on the web. This happens when a piece of content is similar to others for the same search query, and doesn’t bring any new, original, useful or expert views to the table.
For example, writing an article on how to make French toast does not bring anything new to the web:
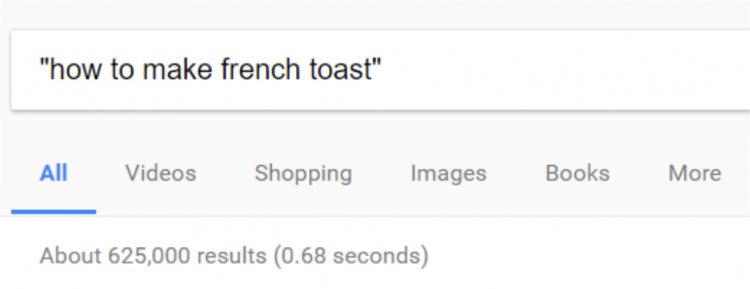
As you can see, there are 625,000 such pages, so it’s unlikely that your web page on how to make French toast will bring anything unique to the table.
A web page like this may have difficulty ranking, as there is likely nothing new in the content, unless you are bringing fresh opinions on the subject that add value, or that are from an expert author users trust.
On the other side of the spectrum, a site offering content that effectively answers questions on a given topic will likely fare well.
Ad Density, Offensiveness and the Page Layout Algorithm
Search engines have learned that sites burdened by too many ads make for a poor user experience. In January 2012, Google announced its, page layout algorithm. With this, Google warned that it would penalize sites with pages that are laden with ads above the fold, and that push the actual content too far down the page.
Trying to figure out if your site is impacted? Try measuring the percentage of the portion of a page above the fold that is occupied by ads. Too high a density might be taken as a negative signal.
In its page layout blog post, Google stressed the algorithm would only affect those sites with pages with an abnormally high number of ads above the fold, relative to the web pages as a whole.
Google also has a patent on detecting annoying or otherwise offensive ads and pages, which patent specialist Bill Slawski discussed in the interview, shortly after Google rolled out its page layout algorithm. You can learn more about how Google rejects annoying ads and pages from Slawski’s in-depth article.
Page Speed and the Mobile Connection
A website’s page speed is important to end users, and therefore, important to Google. After all, Google doesn’t want sites to show up in its results that offer a poor user experience.
In April 2010, Google announced that a website load time is considered a ranking factor. At the time, Google said it affected only about 1 percent of search results. However, as a rule, websites with slow-loading pages can experience higher bounce rates and lower conversions.
Fast-forward to 2015 and the rise of mobile search: there is a need for speed.
As part of Google’s evolving mobile-friendly initiative, Googler Gary Illyes revealed that Google would factor in mobile page speed for ranking mobile sites.
That announcement was followed by Googler John Mueller’s recommendation that mobile page loading speed should be less than two to three seconds.
And, this Google Developers file recommends that above-the-fold content render in one second or less for mobile.
However, with all this, Google still does not use page speed as a significant ranking factor. Unless your site is very slow it’s likely not impacted at all. But, it certainly impacts the user’s impression of your site in dramatic ways.
Language Analysis and User Intent
Language analysis can also help search engines analyze web pages to decipher user intent and this is becoming increasingly important to how search rankings work today.
With language analysis, search engines like Google strive to understand the world more like people do.
Enter RankBrain, RankBrain is a machine learning system that analyzes language across the web to help Google better understand what words, phrases and blocks of content mean.
It then uses that knowledge to better understand user search queries and the user intent behind them, and then picks the best existing Google algorithms to apply to a web page and deliver a search result that best matches user intent.
One way it does this is by noticing patterns in language to determine the best results.
Consider, for example, the traditional search engine approach to ignoring stop words like the and negative words like without in a search query. Now think about how big of an impact ignoring those words could have on the search results for a query like:
Can you get 100% score on Super Mario without walk-through?
Dropping the word without will likely result in the search engine giving the user walk-throughs to help them get a 100% score, which per the query is exactly what they don’t want.
This critical piece in Google’s approach to document analysis helps match the best web pages for any given query, and this is a good thing.
Document Analysis and Reading Level
Reading level refers to the estimated readability of web content. A well-known, standardized formula for gauging this is the Flesch-Kincaid readability tests.
For the purposes of document analysis, the Flesch Reading Ease Test measures the average words per sentence, and the average syllables per word.
The Flesch test is not a measurement of the education level required to read the content (that is the concern of the Kincaid side of the tests). Rather, it is more appropriately thought of as a measurement of the mental effort required to read a given sentence.
Should you want to check the reading level of a document, you can do so using Microsoft Word’s document readability test for content that’s already edited for spelling and grammar.
Obviously, there is no optimal reading level for all web pages. That will be determined by the nature of the website and the sophistication of the content it publishes.
For example, you’d write content appropriate for a younger reading level for a website targeted to children, versus content on the latest advances in artificial intelligence algorithms written for techies.
It’s not clear that Google is using this type of analysis in any manner. However, you could see how knowing the reading level of a document might help them better match a document up with a query, depending on the sophistication level evident in the query.
For example, a query like how to calculate the payoff time of a mortgage suggests that the user wants to understand the algorithm used, and a more technically focused article, which may have a higher grade reading level, might best serve that query.
In contrast, a query like mortgage payoff calculator suggests that the user simply wants to get the answer to the question, so the reading level of the best content for that user might be quite a bit lower.
Whether Google uses this type of analysis or not, it’s useful to know what your audience wants in terms of complexity, and to design your content to meet those expectations.
Conclusion
At the end of the day, search engines are concerned with delivering relevant, fresh content to their users in the results. Understanding how document analysis works and the many factors at play can help website publishers not only improve their web pages, but also their search rankings.
InLogic IT Solutions has a highly dedicated result-oriented SEO team who have solid experience of more than 10 years and certifications too. We have gained a trusted name among the seasoned SEO Companies in Dubai. So, when you connect with us, you are not investing in just a solution but a long term marketing, branding and building trust and valued relationship with all at InLogic IT Solutions. Our SEO Experts Dubai guide you in detailed by knowing your business process and suggesting you the suitable keywords and content material to ensure your online success.
[:ar]
How Search Engines Analyze Web Pages for Search Rankings?
Search engines like Google want to ensure that the quality of the web pages that show up in their search results are high, and that search engine users will be satisfied with them. If their document (web page) analysis shows strong signals that indicate poor-quality content, it can negatively impact the rankings and visibility of those web pages online.
There are many different ways to analyze content quality, and it’s hard to know exactly what the search engines use, but in this article I’ll explore what we do know about what Google is doing in this area, as well as many other concepts that you can use to think about your own web page quality.
What We Know About How Google Evaluates Content Quality
So, what are the signals and related search updates that apply to document analysis? Besides content quality, a brief list would include reading level, keyword usage (stuffing), content “sameness,†ad density, page speed, and finally, language analysis factors.
In the end, for search engines, document analysis is about improving the search user’s experience. Let’s break it down.
The Panda Algorithm
When “content quality†is mentioned, nearly everyone involved in SEO immediately thinks of the Google search ranking algorithm update, Panda.
Since its introduction in February 2011, Panda went through several iterations before finally being folded into Google’s core search ranking algorithm nearly five years later, in January 2016.
Google’s Panda algorithm originally targeted “shallow or low-quality content†represented by the many content farms of the day, as well as websites that “scraped†(copied) others’ content or had “low levels of original content.â€
Of course, Panda still takes aim at such obvious web spam by demoting search rankings, but the algorithm is much more sophisticated today. Now that Panda has become “baked†into Google’s overall search ranking algorithm, it’s become an integral part of weighing content quality factors via document analysis.
And one obvious tip-off indicating low-quality content in document analysis is poor editorial quality. Let’s look at some other factors that might go into web page quality.
Manual Review by Google’s Quality Raters
In 2001, the first version as we knew it of Google’s “Search Quality Rating Guidelines†was leaked on the web (some speculate intentionally). Google’s search evaluation team uses this internal guide to manually review and rate the quality of web pages.
The purpose of the search evaluation team and the manual is to determine what quality looks like, and in turn, use those benchmarks as a feedback loop for Google engineers responsible for developing ranking algorithms.
For example, if an engineer has an idea for tweaking the algorithm, the search evaluation team can help determine if that change has actually improved the search results.
Since that first leak of the Search Quality Rating Guidelines, several other, more current versions also surfaced on the web until Google finally made its full manual officially available to the public, starting in 2015 with several updates since.
Keyword Stuffing and “Vanilla†Content
Keyword stuffing is now so passé that it seems barely worth a mention. A relic of the AltaVista search engine of days of old, it refers to repeating the same keyword over and over on a web page to achieve higher rankings for the term.
The hangover from this tired practice is the notion of “keyword densityâ€. Keyword density is a percentage of the occurrences of a given keyword (or phrase) on a given web page per the total number of all the words of that page. This is also an out-of-date concept.
Keyword stuffing/keyword density is an activity that’s geared towards the search engines rather than the end user. The search engines have long discouraged this practice, as it does not enhance the user experience.
Keyword stuffing, or excessive keyword density, especially when combined with little to no use of synonyms for the key phrase, is a strong indicator of low-quality content.
Similar in effect is content “sameness†or “vanilla†content that doesn’t stand out from other pages on the web. This happens when a piece of content is similar to others for the same search query, and doesn’t bring any new, original, useful or expert views to the table.
For example, writing an article on how to make French toast does not bring anything new to the web:
As you can see, there are 625,000 such pages, so it’s unlikely that your web page on how to make French toast will bring anything unique to the table.
A web page like this may have difficulty ranking, as there is likely nothing new in the content, unless you’re bringing fresh opinions on the subject that add value, or that are from an expert author users trust.
On the other side of the spectrum, a site offering content that effectively answers questions on a given topic will likely fare well.
Ad Density, Offensiveness and the Page Layout Algorithm
Search engines have learned that sites burdened by too many ads make for a poor user experience. In January 2012, Google announced its, page layout algorithm. With this, Google warned that it would penalize sites with pages that are laden with ads “above the fold,†and that push the actual content too far down the page.
Trying to figure out if your site is impacted? Try measuring the percentage of the portion of a page above the fold that is occupied by ads. Too high a density might be taken as a negative signal.
In its page layout blog post, Google stressed the algorithm would only affect those sites with pages with an abnormally high number of ads above the fold, relative to the web pages as a whole.
Google also has a patent on detecting annoying or otherwise offensive ads and pages, which patent specialist Bill Slawski discussed in the interview, shortly after Google rolled out its page layout algorithm. You can learn more about how Google rejects annoying ads and pages from Slawski’s in-depth article.
Page Speed and the Mobile Connection
A website’s page speed is important to end users, and therefore, important to Google. After all, Google doesn’t want sites to show up in its results that offer a poor user experience.
In April 2010, Google announced that a website load time is considered a ranking factor. At the time, Google said it affected only about 1 percent of search results. However, as a rule, websites with slow-loading pages can experience higher bounce rates and lower conversions.
Fast-forward to 2015 and the rise of mobile search: there’s a need for speed.
As part of Google’s evolving mobile-friendly initiative, Googler Gary Illyes revealed that Google would factor in mobile page speed for ranking mobile sites.
That announcement was followed by Googler John Mueller’s recommendation that mobile page loading speed should be less than two to three seconds.
And, this Google Developers file recommends that above-the-fold content render in one second or less for mobile.
However, with all this, Google still does not use page speed as a significant ranking factor. Unless your site is very slow it’s likely not impacted at all. But, it certainly impacts the user’s impression of your site in dramatic ways.
Language Analysis and User Intent
Language analysis can also help search engines analyze web pages to decipher user intent—and this is becoming increasingly important to how search rankings work today.
With language analysis, search engines like Google strive to understand the world more like people do.
Enter RankBrain, RankBrain is a machine learning system that analyzes language across the web to help Google better understand what words, phrases and blocks of content mean.
It then uses that knowledge to better understand user search queries and the user intent behind them, and then picks the best existing Google algorithms to apply to a web page and deliver a search result that best matches user intent.
One way it does this is by noticing patterns in language to determine the best results.
Consider, for example, the traditional search engine approach to ignoring stop words like “the†and negative words like “without†in a search query. Now think about how big of an impact ignoring those words could have on the search results for a query like:
“Can you get 100% score on Super Mario without walkthrough?â€
Dropping the word “without†will likely result in the search engine giving the user walkthroughs to help them get a 100% score, which per the query is exactly what they don’t want.
This critical piece in Google’s approach to document analysis helps match the best web pages for any given query, and this is a good thing.
Document Analysis and Reading Level
Reading level refers to the estimated “readability†of web content. A well-known, standardized formula for gauging this is the Flesch-Kincaid readability tests.
For the purposes of document analysis, the Flesch Reading Ease Test measures the average words per sentence, and the average syllables per word.
The Flesch test is not a measurement of the education level required to read the content (that is the concern of the Kincaid side of the tests). Rather, it is more appropriately thought of as a measurement of the mental effort required to read a given sentence.
Should you want to check the reading level of a document, you can do so using Microsoft Word’s document readability test for content that’s already edited for spelling and grammar.
Obviously, there is no “optimal†reading level for all web pages. That will be determined by the nature of the website and the sophistication of the content it publishes.
For example, you’d write content appropriate for a younger reading level for a website targeted to children, versus content on the latest advances in artificial intelligence algorithms written for techies.
It’s not clear that Google is using this type of analysis in any manner. However, you could see how knowing the reading level of a document might help them better match a document up with a query, depending on the sophistication level evident in the query.
For example, a query like “how to calculate the payoff time of a mortgage†suggests that the user wants to understand the algorithm used, and a more technically focused article, which may have a higher grade reading level, might best serve that query.
In contrast, a query like “mortgage payoff calculator†suggests that the user simply wants to get the answer to the question, so the reading level of the best content for that user might be quite a bit lower.
Whether Google uses this type of analysis or not, it’s useful to know what your audience wants in terms of complexity, and to design your content to meet those expectations.
Conclusion
At the end of the day, search engines are concerned with delivering relevant, fresh content to their users in the results. Understanding how document analysis works and the many factors at play can help website publishers not only improve their web pages, but also their search rankings.
InLogic IT Solutions has a highly dedicated result-oriented SEO team who have solid experience of more than 10 years and certifications too. We have gained a trusted name among the seasoned SEO Companies in Dubai. So, when you connect with us, you’re not investing in just a solution but a long term marketing, branding and building trust and valued relationship with all at InLogic IT Solutions. Our SEO Experts Dubai guide you in detailed by knowing your business process and suggesting you the suitable keywords and content material to ensure your online success.
[:]
I like the helpful information you provide in your articles.
I’ll bookmark your weblog and check again here regularly.
I am quite certain I’ll learn lots of new stuff right here!
Best of luck for the next!